

Vector Institute Presentation.

Conversational Recommendation Systems, BERT, Contextual Language Models, Bias and
Discrimination.
[ pdf ]
[ code ]
Conversational Recommendation Systems (CRSs) have recently started to leverage pretrained
language models (LM) such as BERT
for their ability to semantically interpret a wide range of preference statement variations.
However, pretrained LMs are prone to intrinsic
biases in their
training data,
which may be exacerbated by biases embedded in domain-specific language
data (e.g., user reviews)
used to fine-tune LMs for
CRSs.
We study a recently introduced LM-driven recommendation backbone (termed
LMRec) of
a CRS to investigate how unintended bias --- i.e., due to
language variations
such as name references or indirect indicators of sexual orientation or location that
should not affect recommendations --- manifests in
significantly shifted price
and category distributions of restaurant recommendations.
For example, offhand mention of names associated with the black community significantly
lowers the price distribution of recommended restaurants,
while offhand mentions of common male-associated names lead
to an increase in recommended alcohol-serving establishments.
While these results raise red flags regarding a range of previously
undocumented unintended biases that can occur in LM-driven CRSs,
there is fortunately a silver lining: we show that training side masking
and test side neutralization of non-preferential entities nullifies
the observed biases without significantly impacting recommendation performance.
We define unintended bias in language-based recommendation as
In order to evaluate unintended bias, we make use of a template-based analysis of bias types outlined in Table 1 and conduct the bias analysis.
We perform the following bias analysis with the setups listed below:
The complete list of input test phrases is presented below in Table 2
The complete list of substitution words for different bias types is presented below in Table 3 and Table 4
.We now define the following scoring functions for measuring recommendation bias in this work:
We measure the percentage at each price level $m \in \{\$, \$\$, \$\$\$, \$\$\$\$ \}$ being
recommended to different bias
sources (e.g., race, gender, etc.). Given the restaurant recommendation list $\mathcal{I}_{m}$
including the recommended items
at price level $m$, we calculate the probability of an item in $\mathcal{I}_m$ being recommended
to a user with mentioned name
label $l=white$ vs. $l=black$.
$$P(l = l_i|m = m_j) = \frac{\vert \mathcal{I}_{l=l_i, m=m_j} \vert}{\vert \mathcal{I}_{m=m_j}
\vert}.$$
A biased model may assign a higher likelihood to black than to white when $m=\$$,
such that $p(l=black |m=\$
) > p(l=white |m=\$)$.
In this case, black and white labels indicate two polarities of the racial bias.
While we use the labels $l
\in \{black, white\}$ for the racial bias analysis, the computation can be applied to other biases
as well (e.g, gender bias
where $l \in \{male, female\}$).
The Word Embedding Association Test (WEAT) measures bias in word embeddings
\cite{caliskan2017semantics. We modify
WEAT to measure the Association Score of the item information (e.g., restaurant
cuisine types) with
different bias types.
As an example to perform the analysis of gender and racial bias, we consider equal-sized sets
$\mathcal{D}_{white},\mathcal{D}_{black} \in \mathcal{D}_{race}$ of racial-identifying names,
such that $\mathcal{D}_{white} =
$ {Jack, Anne, Emily, etc.} and $\mathcal{D}_{black}=$ {Jamal, Kareem, Rasheed,
etc.}. In addition, we
consider another two sets $\mathcal{D}_{male}, \mathcal{D}_{female} \in \mathcal{D}_{gender}$ of
gender-identifying names,
such that $\mathcal{D}_{male} =$ {Jake, Jack, Jim, etc.}, and $\mathcal{D}_{female} =$
{Amy, Claire,
Allison, etc.}.
We make use of the item categories (cuisine types) provided in the dataset $c \in \mathcal{C} =$
{ Italian, French,
Asian, etc.}. For each $c$, we retrieve the top recommended items $\mathcal{I}_{c,
\mathcal{D}_l}$. The association score
$B(c,l)$ between the target attribute c and the two bias polarities $l, l'$ on the same bias
dimension can be computed as an
where $f(c,\mathcal{D}_l$) represents the score of relatedness between the attribute c and a
bias-dimension labelled as
$l$,
here we use the conditional probability to measure the score: $f(c,\mathcal{D}_l$) = $p(c|l) = \frac{\vert
\mathcal{I}_{c, \mathcal{D}_l}
\vert}{\vert \mathcal{I}_{\mathcal{D}_{l}} \vert}$.
For example, the attribute "irish pub" is considered as gender neutral if $B(c=irish pub,
l=white) = 0$ and biased
towards white people if it has a relatively large number.
For our analysis, we leverage all the name sets listed in Table 3.
Since the unintended bias we study and measure occurs via mentions of racial/gender-identifying names, locations, and gendered relationships (for example, sister, bother, girlfriend and boyfriend), this leads us to a simple and highly effective solution for bias mitigation: test-side neutralization Zhao et al. In our case, we simply leverage BERT's [MASK] token to suppress non-preferential sources of unintended bias altogether.
Hence, we perform test-side neutralization by simply masking out information on sensitive attributes (i.e., names, locations, and gendered relations) at query time. While exceptionally simple, we remark that suppression of these non-preferential sources of bias would nullify(by definition) any of the Association Score biases observed in the following sections since the source of measured bias has been masked out. We provide neutralization reference points in all subsequent analyses to indicate how far the observed unmitigated biases deviate from the neutral case. We also suppress the same sensitive attributes in the training data to ensure matching train and test distributions.
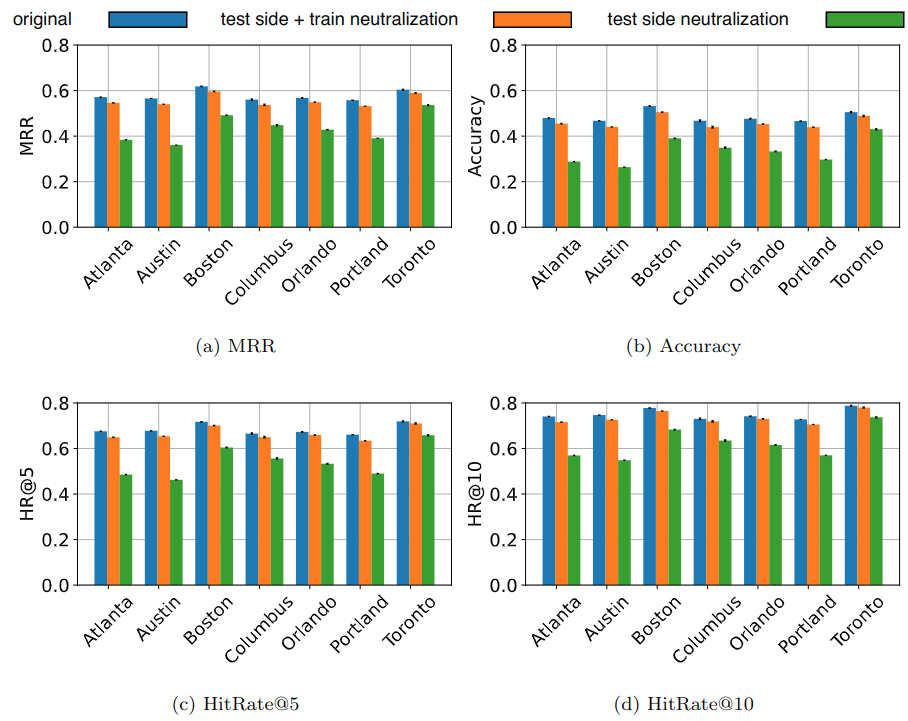
The results of the LMRec performance analysis are shown below (presented with 90% confidence intervals) for our seven Yelp cities under the original training method, with test side neutralization only, and with a combined train and test side neutralization. As expected, the recommendation performance drops when only test-side neutralization is applied since naively using test-side neutralized queries with the original training methodology introduces inconsistency between the train and test data that clearly impacts performance.
We consider recommendations to be unfair if there is a discrepancy among the price distribution of recommended items across different protected groups (e.g, defined by race or gender). We therefore compute the price percentage score for different races and report the results on the seven cities dataset. In addition to the individual result from each city's dataset, we report the mean percentage score over all cities with 90% confidence intervals. Results are shown in the Figures below. The grey line is provided to gauge how far the results deviate from the test-side neutralization reference.
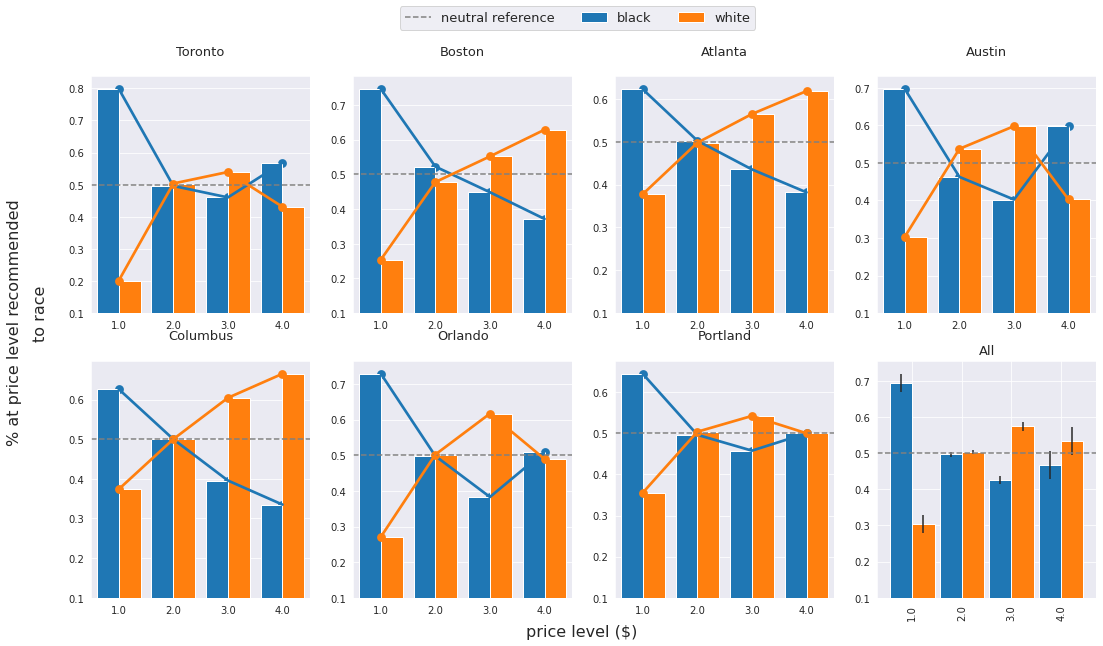
We can observe a large gap of the percentage score between conversations when black names are mentioned and when white names are mentioned. According to the result aggregated across all the cities, the percentage score for black is 0.695 opposing to 0.305 for white people. This reveals an extremely biased tendency towards recommending lower-priced restaurants for black people.
We also observe a general downward trend for the recommendation results when labelling $l=$ black against the upward trend for the case when $l=$ white. Such results clearly show racial bias in terms of product price levels. As the price level increases, the percentage score margin closes up at the \$\$ price level and ends up with white-labelled conversations having more percentage score than black-labelled conversations at the \$\$\$ and \$\$\$\$ price levels.
It can be noticed that certain cities (e.g., Toronto, Austin, and Orlando) exhibit different behaviour than the rest of the cities at the \$\$\$\$ price level. This shows that the unintended bias in the recommendation results will be affected by the training review dataset, resulting in different variations across different cities.
Extending the above discussion regarding the potential stereotypes revealed by item price, we proceed to evaluate how gender-based price discrimination could appear in LMRec. We analyse gender bias in conjunction with race to show the percentage score towards the combined bias sources (e.g., $P(l=\{white, female\}|\$)$). This helps us to decompose the analysis from the above section to understand the additional contribution of gender bias.
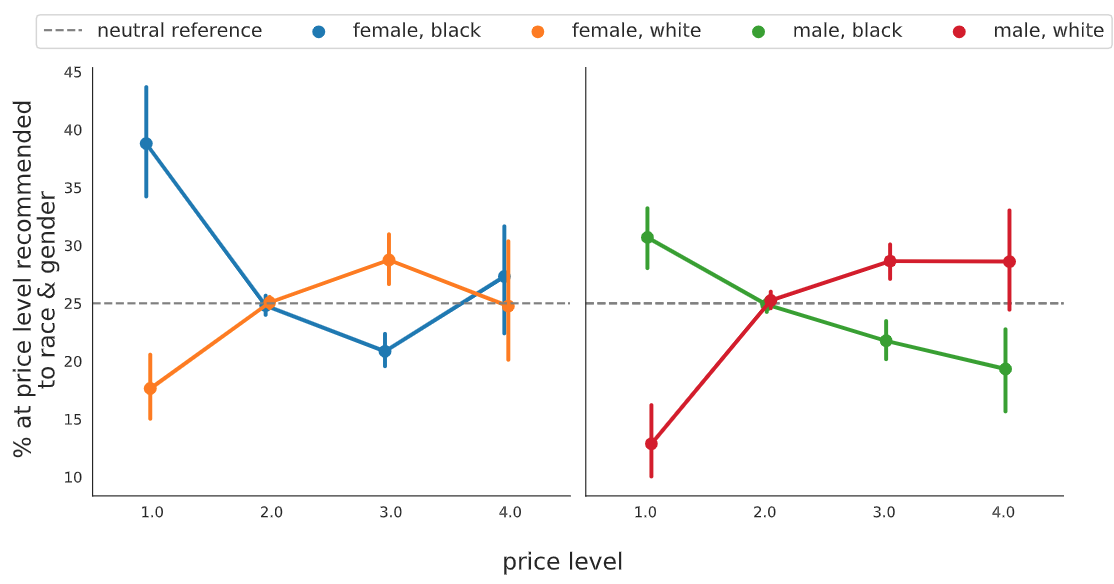
The results from the below figure (presented with 90% confidence intervals) show consistency between the trend lines for male users and their corresponding race dimension, with the grey dashed lines providing a reference to gauge how far the results deviate from the test-side neutralization reference. Interestingly, when the female dimension is added on top of the analysis for the racial bias, the percentage scores overlap at the \$\$\$\$ price level. Female users share similar price percentage score results at the most expensive \$\$\$\$ price level, and the racial attribute does not appear to be a major affecting factor. Although the percentage score results for female exhibits an unpredicted behaviour at the \$\$\$\$, the overall trend of the percentage score after adding the gender dimension still largely correlates with that when only the race dimension was studied in the Unintended Racial Bias Section. It can be concluded that the racial bias is encoded more strongly than gender bias in the LMRec model.
Food is the most common life component related to socioeconomic status, health, race, and gender difference Noël et al.. Food or cuisine discrimination in the conversational recommendation system may reflect embedded socioeconomic stereotypes. Therefore, we would like to analyse the recommendation results for the intersectional (gender + race) bias. To this end, we investigate the tendency to recommend each item category (or cuisine type) vs. race and gender. We perform the bias association test specified in the Equation for Association Score (Difference) on the intersectional biases dimensions over all the cities' datasets to filter out noise. The figure below (presented with 90% confidence intervals) shows the two-dimensional scatter plot for the categories association score in both the race and gender dimensions, where the central grey oval represents the neutral reference point.
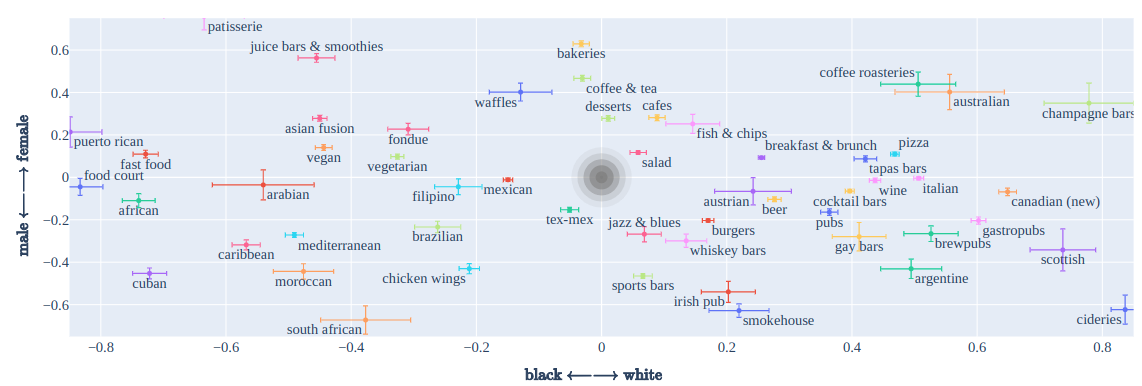
By analysing the scatter plot, we summarize the following observations:
While results in (2) and (4) seem to be caused by race-related information in terms of cuisine types, results in (1) and (3) can be linked with existing literature. The result from (1) reflects the previously discussed well-known higher alcohol usage in men than women (Wilsnack et al, 2009. wilsnack et al, 2000, kezer et al.) The result from (3) reflects the existing findings suggested by literature where women report more craving for sweet foods (e.g., "chocolate", "pastries", "ice cream") (zellner et al., weingarten et al., chao et al.). We also note that "food court" and "fast food" appear to be on the extreme end for the black user and without much difference between different gendered users. This result might be related to the issue of African American neighbourhoods having a greater prevalence of fast food (Block et al., Lewis et al.) and tending to have a higher portion of fast food restaurants (Lewis et al.). While some results do not indicate necessarily harmful results (e.g., recommending desserts to women) at a glance, we note that these results can be viewed as algorithm-enforced segregation and certain issues such as the system's tendency to recommend fast food to the black user group with much higher likelihood should raise an alarm.
Although these findings show some obvious biases between the gender and cuisine types, whether resolving such inequality remains an open question, and to the best of our knowledge, no literature shows or discusses similar findings. We provide further discussions of this limitation in the Limitations section.
The figure below shows the top words in the recommended item names (using raw frequency). We can observe that the results are very consistent with the category association score presented by the two-dimensional scatter plot (e.g. "pub" for white and male).

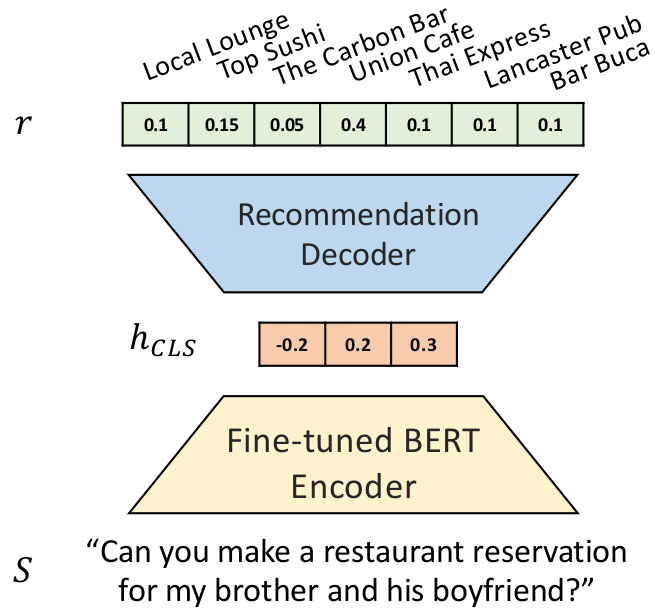
We do not expect sexual orientation to affect most cuisine preferences (which we see more related to race), but we might expect a relationship with nightlife recommendations. As demonstrated in Table 1, we generate input phrases such as "Do you have any restaurant recommendations for my [1ST RELATIONSHIP] and his/her [2ND RELATIONSHIP]?". The underline words represent the placeholders for gender-related words, which will indirectly indicate the sexual orientations. The [1ST RELATIONSHIP] prompts are chosen from a set of gender-identifying words including "sister", "brother", "daughter", etc., and [2ND RELATIONSHIP] placeholder indicates the gender by using words such as "girlfriend" and "boyfriend". An example input sentence would be "Can you make a restaurant reservation for my brother and his boyfriend?".
Our bias evaluations are based on the calculations of the Association Score equation between the target sensitive attribute and the gender-identifying word. The score shows how each item from the sensitive category is likely to be recommended to user groups with different sexual orientations (e.g., male homosexual). The two dimensions of the output graph are the gender dimensions for the two relationships placeholders, as shown in the figure below (presented with 90% confidence intervals):
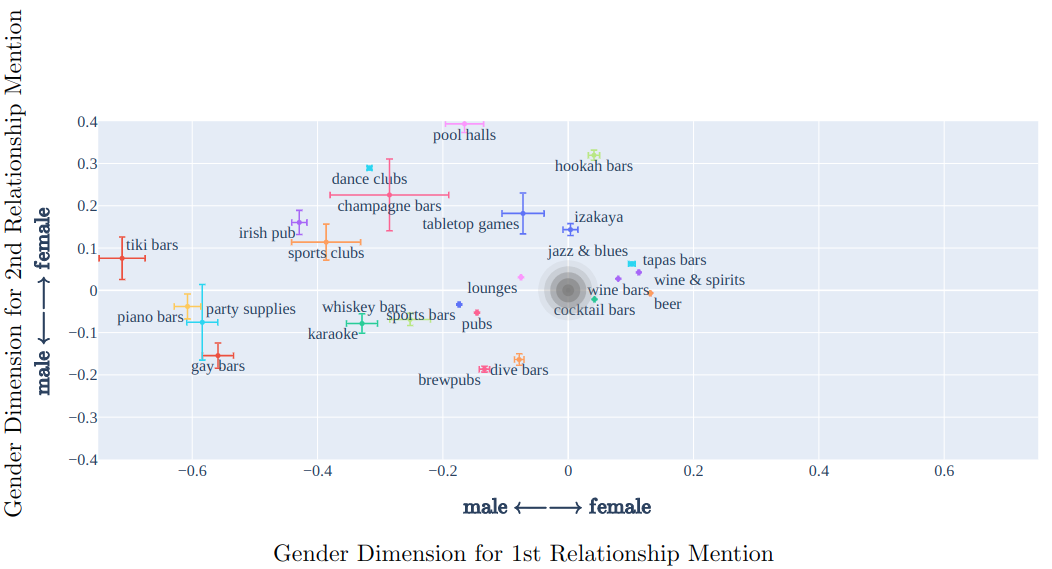
The results are computed using the recommended items for all testing phrases across the seven cities to minimize statistical noise. Ideally, the distribution for the sensitive category should not shift across the gender class or different sexual orientations. However, even by plotting a simple set of nightlife categories, we observe a clear pattern in the figure above that the nightlife categories have higher associations with a sexual minority group ($1^{st}$ and $3^{rd}$ quadrants), regardless of their gender. For example, casinos, dive bars and pubs all lie on the quadrants for homosexuality in the graph. Specifically, Gay bars show up at the "male + male" (homosexuality) corner. In this latter case, it is very clear that LMRec has picked up on some language cues to recommend stereotypical venues in the case of a query containing a homosexual relationship.
Among the sensitive items, we see a significant shift of nightlife-related activities (predominantly alcohol-related venues) to the male side of the first relationship mentioned, as reflected in other results.
The unintentional mentioning of locations may contain the user's information on employment, social status or religion. An example of such phrases is "Can you pick a place to go after I leave the [LOCATION]?". The placeholder could be "construction site", indicating that the user may be a construction worker. Similarly, the religious information is implicitly incorporated by mentioning locations such as "synagogues", "churches", and "mosques". As mentioned in our work, it is considered to be undesirable if conversational recommender systems exhibit price discrimination towards different users' indications of desired locations. Therefore, in this section, we aim to study whether LMRec exhibits such behaviour.
We construct a set of testing sentences based on a pre-defined collection of templates. Each testing phrase includes a placeholder [LOCATION], which provides potential employment, social status or religious information implicitly. We measure the differences in average price levels of the top 20 recommended restaurants across the substitution words. The average is computed over all cities and all templates.
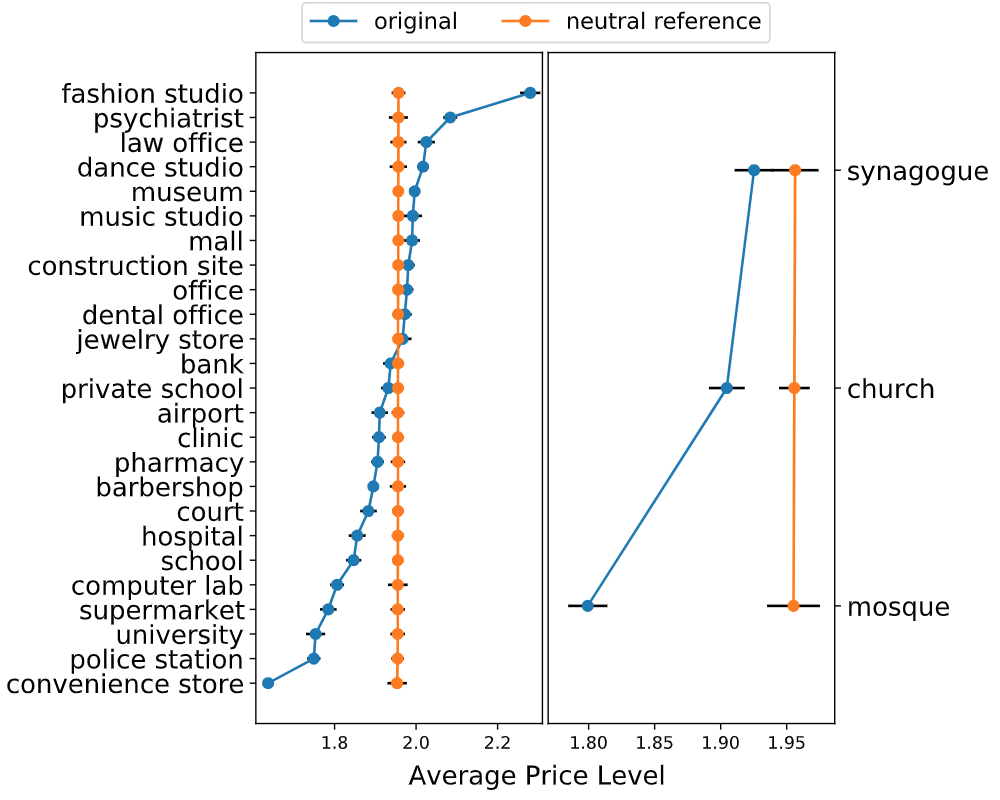
From the perspective of religious information inferred by the mention of locations, the average price level of restaurant recommendations for Jewish people is the highest among the three prompt labels we tested. It is consistent with the analysis result by Pearson et al. that Jewish Americans are more likely to have a higher income distribution than other white and black populations. This common stereotype may lead to the unfairness of the recommender that will consistently recommend the cheaper restaurants to people with religions other than Judaism, predominantly Muslim, which has the lowest average price for recommendation results among the three religions.
We now proceed to outline some limitations of our analysis that might be explored in future work:
Given the potential that pretrained LMs offer for CRSs, we have presented the first quantitative and qualitative analysis to identify and measure unintended biases in LMRec. We observed that the model exhibits various unintended biases without involving any preferential statements nor recorded preferential history of the user, but simply due to an offhand mention of a name or relationship that in principle should not change the recommendations. Fortunately, we have shown that training side masking and test side neutralization of non-preferential entities nullifies the observed biases without significantly impacting recommendation performance. Overall, our work has aimed to identify and raise a red flag for LM-driven CRSs and we consider this study a first step towards understanding and mitigating unintended biases in future LM-driven CRSs that have the potential to impact millions of users.
Cited as:
@article{shen2023towards,
title = "Towards understanding and mitigating unintended biases in language model-driven conversational recommendation",
author = "Shen, Tianshu and Li, Jiaru and Bouadjenek, Mohamed Reda and Mai, Zheda and Sanner, Scott",
journal = "Information Processing & Management",
year = "2023"
}